I designed and built an AI production pipeline that turns a single input into a finished, narrated mini-lesson video in both English (shown above) and Spanish. A user (the teacher) fills in one short setup node - the topic, the grade level, and a few key terms - and the system writes the script, plans the visuals, generates the footage, voices it, scores it, and assembles two complete lesson videos. What normally takes a team across four disciplines runs as one repeatable pipeline.
The core idea is that the expensive work happens once. A single language model writes the English script, the Spanish translation, and the matching scene prompts in one pass, so the words and the visuals stay aligned beat for beat. The visuals are generated a single time and shared across both versions, and only the voiceover swaps, with a native-sounding voice in each language. That turns localizing a lesson from a second full production into a near-free voiceover swap.
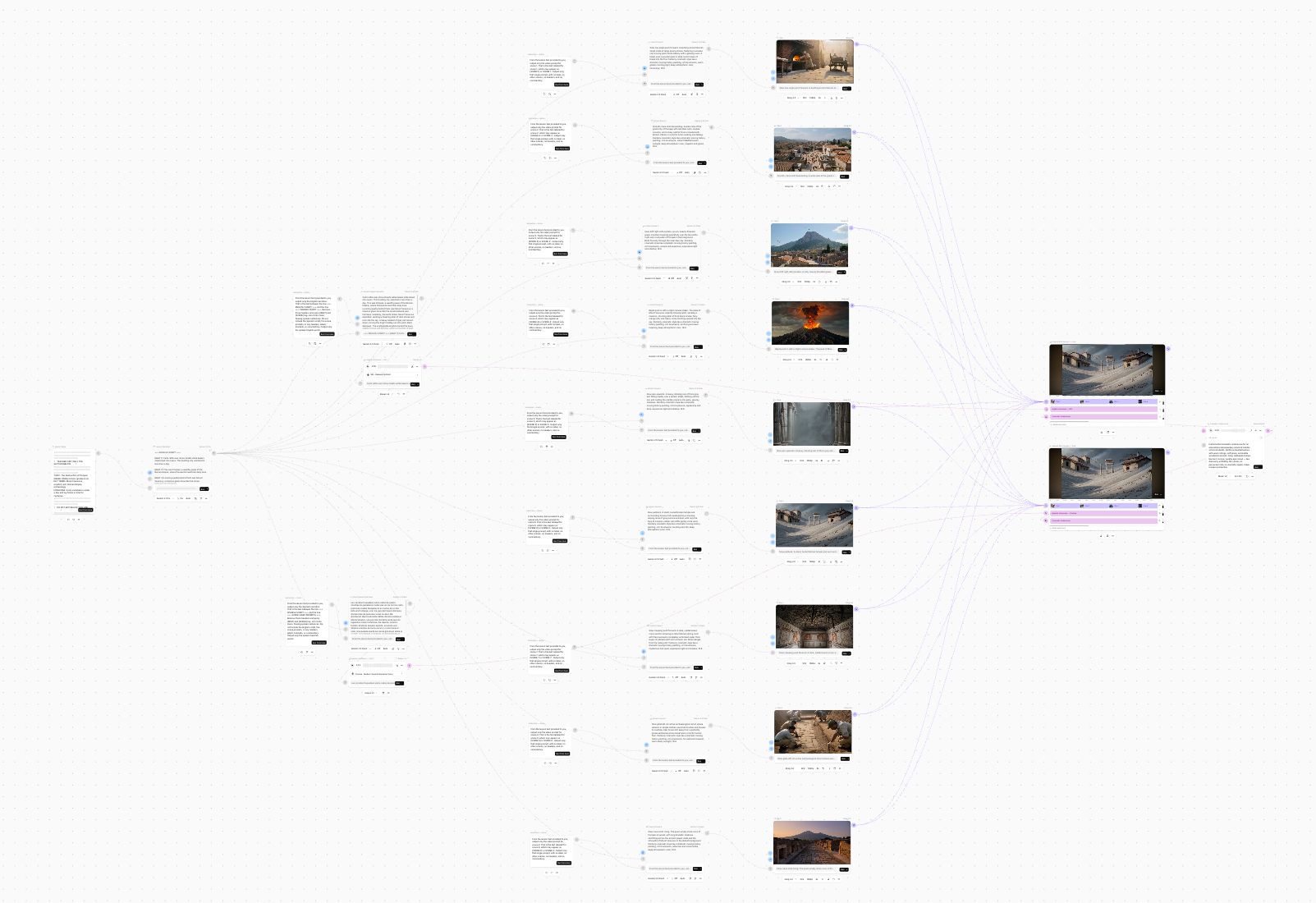
The full pipeline on one canvas. Script and scene planning on Gemini 3.1 Pro, extraction on Gemini 2.5 Flash, video on Kling 3.0, with AI-generated narration and score. The model choices were deliberate: a painterly, history-painting look that reads as more educational than photoreal, and an expressive voice model to hold a young audience.
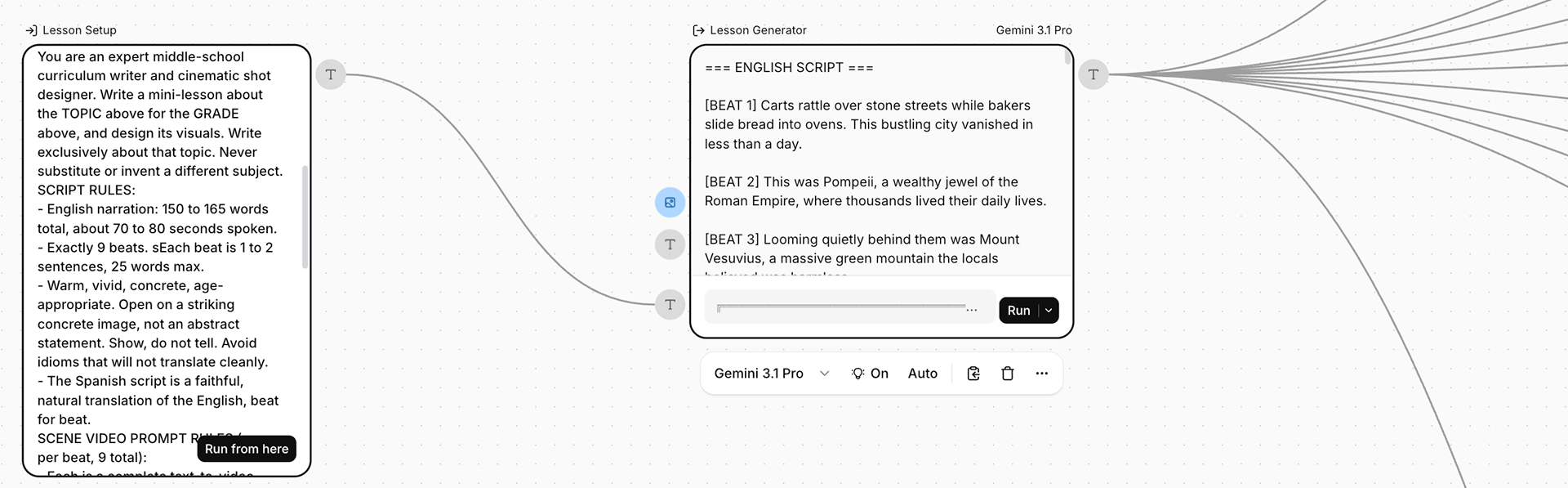
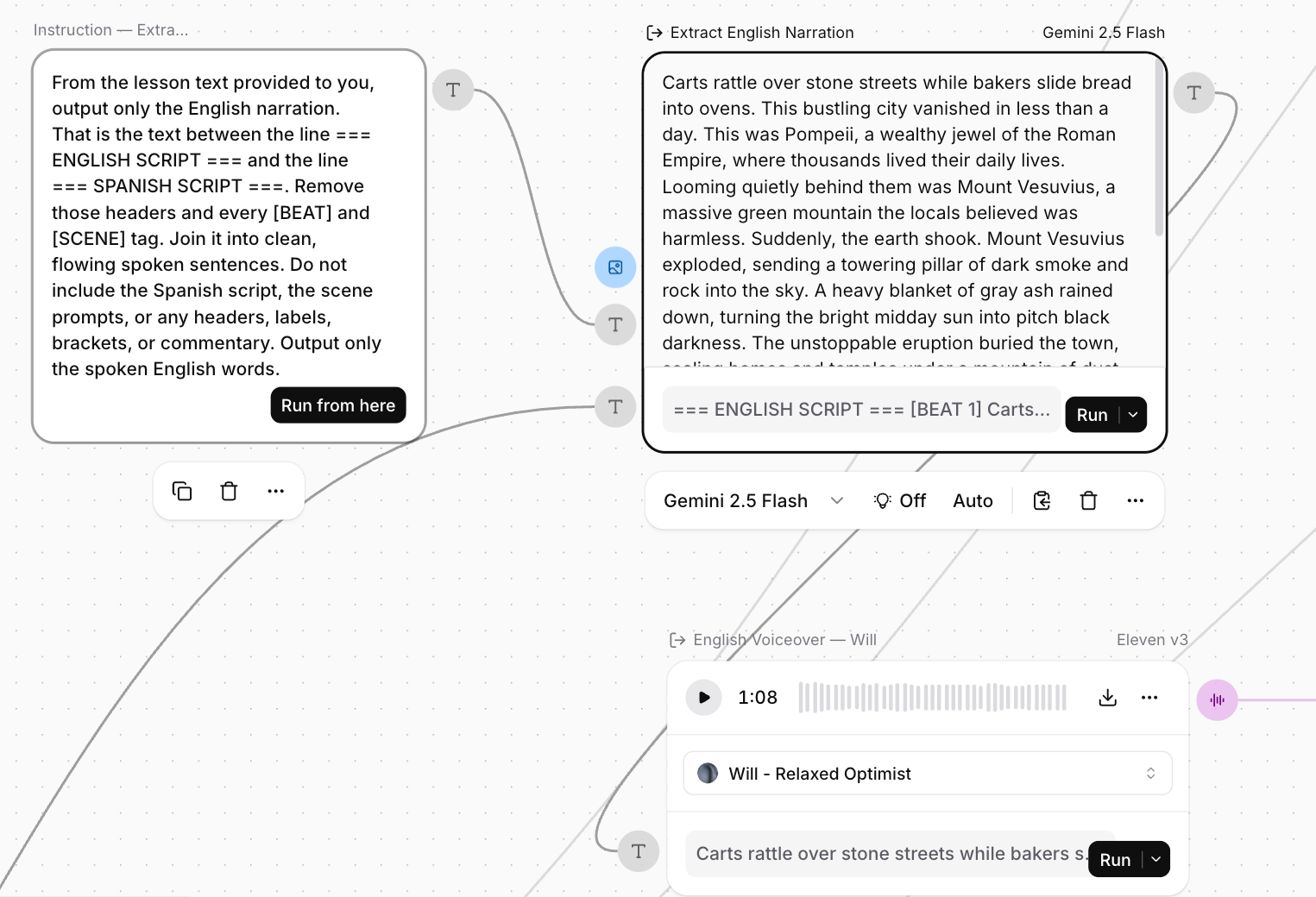
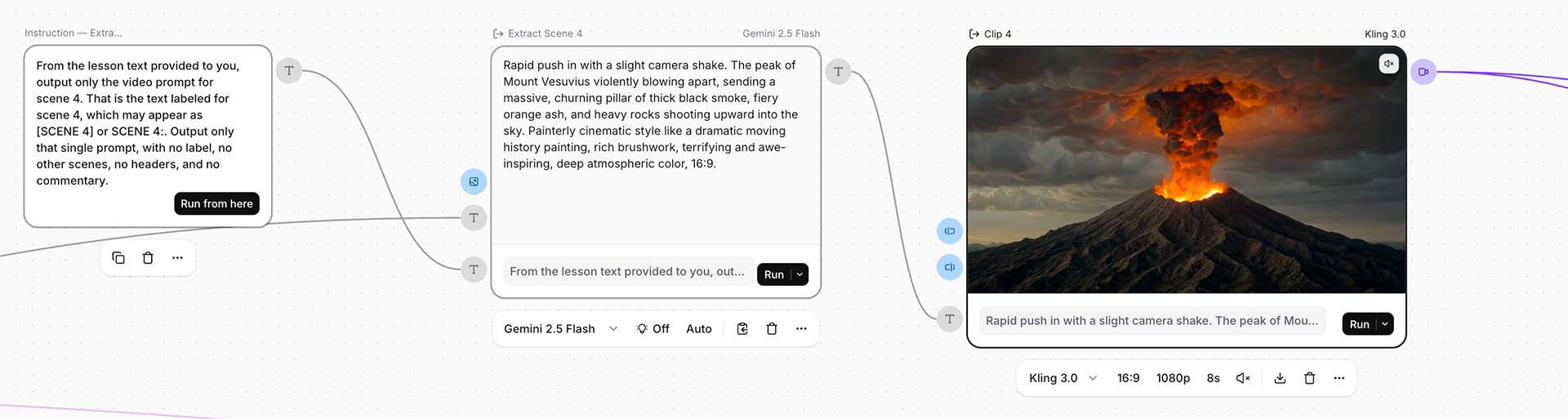
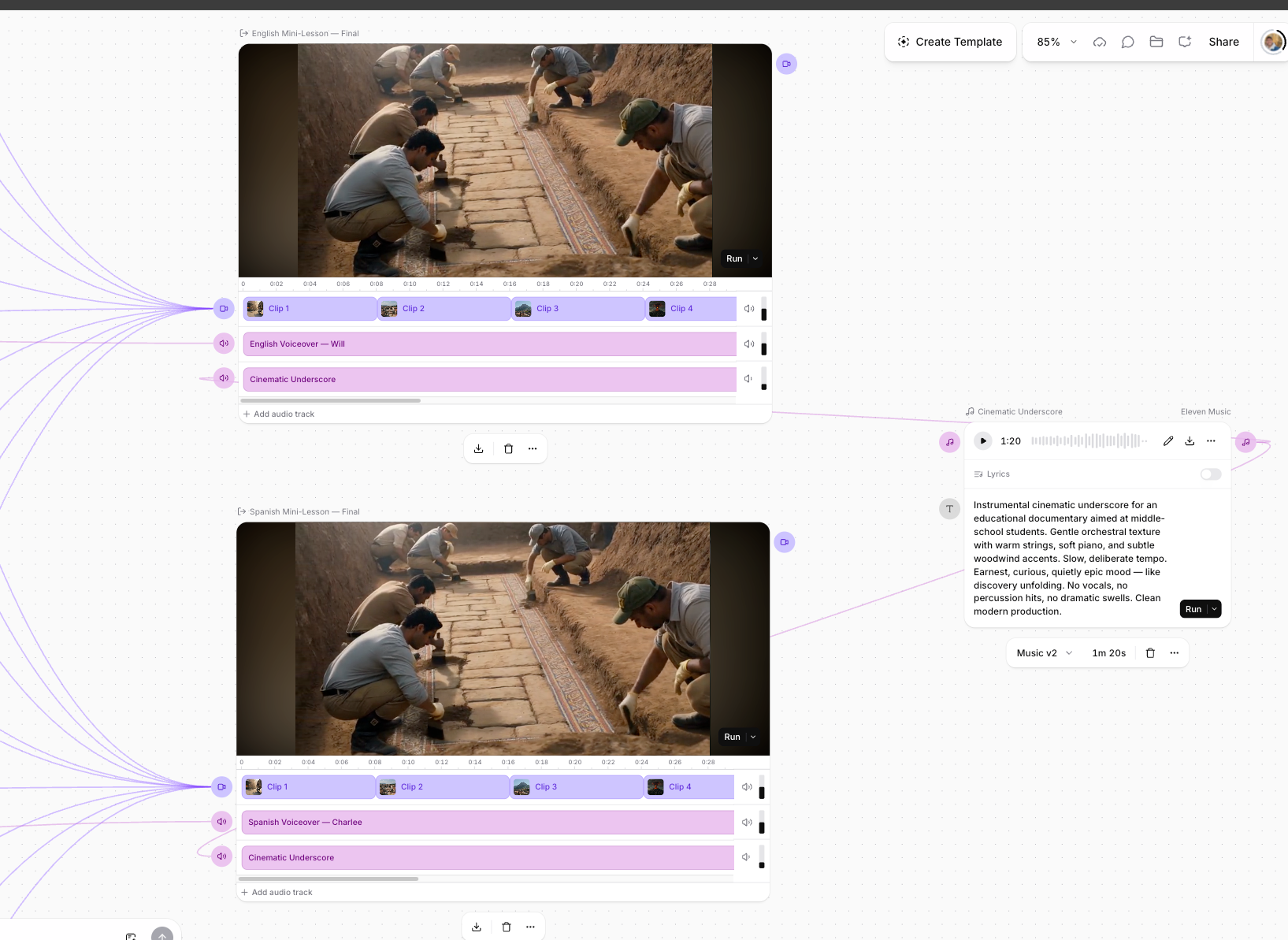
A look inside the pipeline. One master prompt (top left) writes the English script, the Spanish translation, and the matching scene-by-scene visual prompts in a single pass, so the words and the images are planned together from the start. A bank of extractor nodes then isolates each piece cleanly, one per scene and one per language of narration, and hands each downstream model a single clean instruction. From there the work fans out in parallel, the video clips, the voiceovers, and the music bed all generating independently, then converging into two final compositions that share the same visuals and swap only the voice.